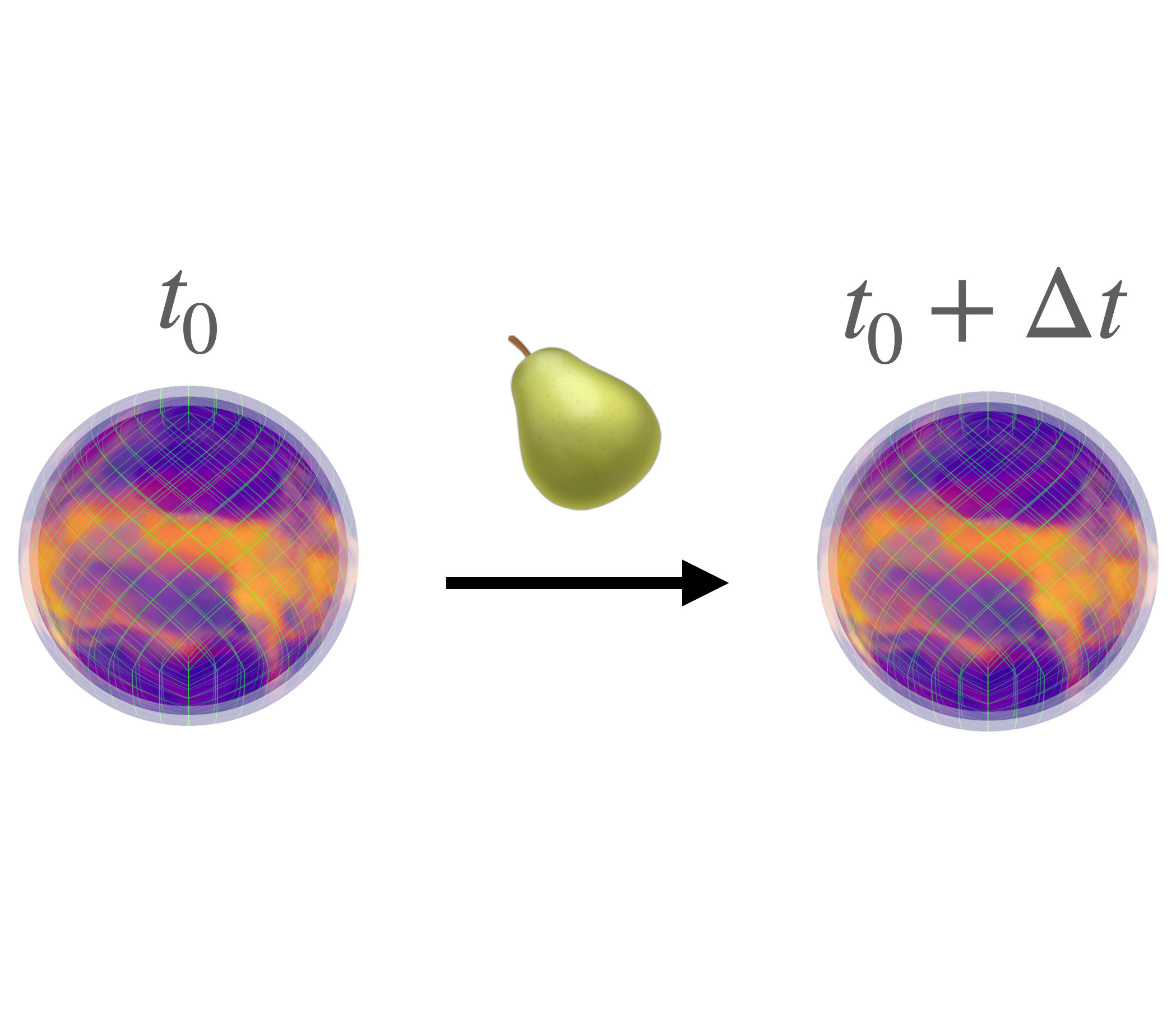
We organize the GAPinDNNs seminar at the Department for Mathematical Sciences at Chalmers and the University of Gothenburg.
The topics of the seminar are broad and lie at the intersection of machine learning (in particular deep learning), pure mathematics and theoretical physics. We have both more theoretical and more applied speakers. If you would like to receive invitations to upcoming talks, please let the seminar organizers know and we will add you to our email list.
Seminars usually happen in-person only on Wednesdays at 1.15pm. Before the seminar we go for lunch with the speaker and there is a speaker dinner in the evening before or after the talk.
Current seminar organizers are Jan Gerken and Daniel Persson.
Link to subscribe to the calendar: https://gapindnns.github.io/downloads/calendar.ics
(In your favourite calendar app, you can subscribe to this link to get constant updates on the schedule.)
Diffusion models have achieved state-of-the-art performance in generating images, videos, scientific data, and even text. Despite its broad practical success, neural-network-based generative diffusion is, in theory, condemned to memorize the training set rather than learn the underlying data-generating distribution. This talk will first present recent advances in understanding the surprising generalization capabilities of diffusion models. We will argue that, in this framework, generalization can be understood as an intermediate and necessary dynamical stage that precedes memorization. We will then discuss how diffusion models can progressively transition from generalizing to memorizing the data, highlighting a counterintuitive sampling behavior that arises in this still largely unexplored regime. The talk will present both theoretical insights and open questions on the generative capabilities of diffusion models, while fostering the quest for a new definition of generalization in generative modeling.
To understand the inductive bias and generalization capabilities of large, overparameterized machine learning models, it is essential to analyze the dynamics of their training algorithms. Using dynamical mean field theory we investigate the learning dynamics of large two-layer neural networks. Our findings reveal that, for networks with a large width, the training process exhibits a separation of timescales phenomenon. This leads to several key observations:
Joint work with Andrea Montanari.
Bayesian analysis of deep neural networks has largely been unsuccessful, often resulting in significant under- or over-fitting. We argue that this is due to inappropriate treatment of the overparametrization that trivially follows from increasing network size. We give a geometric characterization of overparametrization and show that respecting this geometric structure results in significant improvements to Bayesian approximations. We further discuss the numerical aspects.
Neural ODEs are geometric deep learning models based on the flows generated by vector fields. The ODEs corresponding to these flows describe the dynamics of information propagating through various geometries, and training amounts to learning the vector field that minimizes the loss in some machine learning application. Neural ODEs have been used to construct powerful generative models, in particular using the flow matching training paradigm, that can account for both the geometry and the symmetries of a problem, e.g., to generate 3D protein structures. In this talk I will discuss the NODE framework on manifolds and in particular some open problems that prompt us to revisit the role of geometry in these deep learning models, adding more geometrical structure to the manifolds or even moving beyond the manifold concept itself.
What is the best way to make a neural network respect a symmetry in the data? Some say that it is better to build models that always respect the symmetry, while others say that it is better to rely on training on symmetric(augmented) data. There is empirical work pointing in both directions, and likewise reasonable arguments for both viewpoints. In this talk , we will present some theoretical results that compare and connect the different strategies. The main insight is that the geometry of the underlying architecture plays a role in it being able to learn symmetries.
Lagrangian mechanics provides a powerful framework for modeling the dynamics of physical systems by inferring their motions based on energy conservation. This talk will explore recent advances in applying geometric perspectives, particularly Riemannian geometry, to Lagrangian principles for predicting and optimizing motion dynamics. First, I will discuss how the dynamic properties of humans and robots are straightforwardly accounted for by considering geometric configuration spaces. Second, I will show how this geometric approach can be extended to generate dynamic-aware, collision-free robot motions by modifying the underlying Riemannian metric. Finally, I will consider the problem of learning unknown high-dimensional Lagrangian dynamics. I will present a geometric architecture to learn physically-consistent and interpretable reduced-order dynamic parameters that accurately capture the behavior of the original system.
Symmetries (transformations by group actions) are present in many datasets, and leveraging them holds significant promise for improving predictions in machine learning. In the work I will present, we aim to understand when and how deep networks can learn symmetries from data. We focus on a supervised classification paradigm where data symmetries are only partially observed during training: some classes include all transformations of a cyclic group, while others include only a subset. We ask: can deep networks generalize symmetry invariance to the partially sampled classes? To answer this question, we derive a neural kernel theory of symmetry learning. We find a simple characterization of the generalization error of deep networks on symmetric datasets, and observe that generalization can only be successful when the local structure of the data prevails over its non-local symmetric structure, in the kernel space defined by the architecture. Our framework also applies to equivariant architectures (e.g., CNNs), and recovers their success in the special case where the architecture matches the inherent symmetry of the data. Empirically, our theory reproduces the generalization failure of finite-width networks (MLP, CNN, ViT) trained on partially observed versions of rotated-MNIST. We conclude that conventional networks trained with supervision lack a mechanism to learn symmetries that have not been explicitly embedded in their architecture a priori. Our framework could be extended to guide the design of architectures and training procedures able to learn symmetries from data.
Fully-connected deep neural networks with weights initialized from independent Gaussian distributions can be tuned to criticality, which prevents the exponential growth or decay of signals propagating through the network. However, such networks still exhibit fluctuations that grow linearly with the depth of the network, which may impair the training of networks with width comparable to depth. I will provide some theoretical and experimental evidence that using weights initialized from the ensemble of orthogonal matrices leads to better training and generalization behavior even for deep networks, and argue that these results demonstrate the practical usefulness of finite-width perturbation theory.
Starting from simple curve fitting problems, I will explain how modern AI works by learning a large number of features from data: wide neural networks fit data to linear combinations of many random features, and stacking layers to form deep neural networks allows the features to evolve according to data. It has been empirically observed that the performance of neural networks scales as power laws with respect to the sizes of the model and training data set. I will discuss a recently proposed random feature model that captures the physics of neural scaling laws, and its solution in an effective theory framework using large-N field theory methods. The solution reveals a duality that is indicative of a deeper connection between neural networks and field theories.
The NN-QFT correspondence provides a description of a statistical ensemble of neural networks in terms of a quantum field theory. The infinite-width limit is mapped to a free field theory while finite N corrections are taken into account by interactions. In this talk, after reviewing the correspondence, I will describe how to use non-perturbative renormalization in this context. An important difference with the usual analysis is that the effective (IR) 2-point function is known, while the microscopic (UV) 2-point function is not, which requires setting the problem with care. Finally, I will discuss preliminary numerical results for translation-invariant kernels. A major result is that changing the standard deviation of the neural network weight distribution can be interpreted as a renormalization flow in the space of networks.
Based on arXiv:2108.01403 and arXiv:2212.11811.
The short answer to the title is NO, but there are some theoretical connections between neural networks with self-supervised pre-training and kernel principal component analysis. At a high level, the equivalence is based on two ideas: (i) optimal solutions for many self-supervised losses correspond to spectral embeddings; and (ii) infinite-width neural networks converge to neural tangent kernel (NTK) models.
I will first give a short overview of this equivalence and discuss why it could be useful for both theory and practice of foundation models. I will then discuss two recent works on the NTK convergence under self-supervised losses (arXiv:2403.08673, arXiv:2411.11176). Specifically, I will show that one cannot directly use NTK results from supervised learning / regression, but a careful analysis is needed to prove that the NTK indeed remains constant during self-supervised training.
Numerical linear algebra underpins all computational sciences, machine learning not the least. But what if machine learning could return the favor by learning numerical algorithms tailored to a particular problem class? In this talk, I will highlight the connection between matrices and graph, and argue that this makes graph neural networks a natural fit for learning task-specific numerical algorithms.
In this talk, I will present how algebraic geometry provides a framework to study neural networks by using polynomials to approximate their activation functions. This approach allows us to view the function spaces of neural networks, or neuromanifolds, as semi-algebraic varieties. I will discuss key algebraic properties of these neuromanifolds, such as their dimension and degree, and their role in governing fundamental aspects of network behavior, including expressivity and sample complexity. Singularities in the neuromanifold further shape the training process, introducing implicit biases that influence optimization paths and generalization. Finally, I will describe the relationship between the global geometry of neuromanifolds and optimization dynamics, focusing on the impact of algebraic invariants on the loss landscape.
Visualization and uncertainty quantification are often used to support our interpretation of deep learning models. In this talk, we show through examples how both visualization and uncertainty quantification can lead to misinterpretation if applied naïvely. Our examples will include equivariant neural networks for graphs and images, as well as uncertainty quantification with structured label variation.
Equivariance imposes symmetry constraints on the connectivity of neural networks. This talk investigates the case of equivariant networks for fields of feature vectors on Euclidean spaces or other Riemannian manifolds. Equivariance is shown to lead to requirements for 1) spatial (convolutional) weight sharing, and 2) symmetry constraints on the shared weights themselves. We investigate the symmetry constraints imposed on convolution kernels and discuss how they can be solved and implemented. A gauge theoretic formulation of equivariant CNNs shows that these models are not only equivariant under global transformations, but under more general local gauge transformations as well.
Neural networks parametrize spaces of functions, sometimes referred to as `neuromanifolds’. Their geometry is intimately related to fundamental machine learning aspects, such as expressivity, sample complexity, and training dynamics. For polynomial activation functions, neuromanifolds are (semi-) algebraic varieties, enabling the application of tools and ideas from algebraic geometry to deep learning. In this talk, we will first review the general theory of neuromanifolds, and then present our recent results for deep convolutional networks with monomial activations. In this case, we show that the parametrization is finite, birational, and regular, factoring through the Segre-Veronese embedding. Moreover, by appealing to the theory of the generic Euclidean distance degree, we compute the number of critical points of the (complexified) regression objective for a generic large dataset.
Neural ODEs are neural network models where the network is not specified by a discrete sequence of hidden layers. Instead, the network is defined by a vector field describing how the data evolves continuously over time governed by an ordinary differential equation (ODE). These models can be generalized for data living on non-Euclidean manifolds, a concept known as manifold neural ODEs. In our paper, we develop a geometric framework for equivariant manifold neural ODEs. Our work includes a novel formulation of equivariant neural ODEs in terms of differential invariants, based on Lie theory for symmetries of differential equations. We also construct augmented manifold neural ODEs and show that they are universal approximators of equivariant diffeomorphisms on any path-connected manifold.
The field of causality has recently emerged as a subject of interest in machine learning, largely due to major advances in data collection methods in the biological sciences and tech industries where large-scale observational and experimental data sets can now be efficiently and ethically obtained. The modern approach to causality decomposes the inference process into two fundamental problems: the inference of causal relations between variables in a complex system and the estimation of the causal effect of one variable on another given that such a relation exists. The subject of this talk will be the former of the two problems, commonly called causal discovery, where the aim is to learn a complex causal network from the available data. We will give a soft introduction to the basics of causal modeling and causal discovery, highlighting where combinatorics and geometry have already started to contribute. Going deeper, we will analyze how and when geometry and combinatorics help us identify causal structure without the use of experimental data.
We start from geometric first principles to construct a machine learning framework for 3D point set analysis. We argue that spherical decision surfaces are a natural choice for this type of problems, and we represent them using a non-linear embedding of 3D Euclidean space into a Minkowski space, represented by a 5D Euclidean space. Via classification experiments on a 3D Tetris dataset, we show that we can get a geometric handle on the network weights, allowing us to directly apply transformations to the network. The model is further extended into a steerable filter bank, facilitating classification in arbitrary poses. Additionally, we study equivariance and invariance properties with respect to \(O(3)\) transformations.
In this talk I present an overview to my recently defended PhD thesis conducted within the WASP program. While artificial intelligence and deep learning have revolutionized many fields in the last decade, one of the key drivers has been access to data. This is especially true in biomedical image analysis where expert annotated data is hard to come by. The combination of Convolutional Neural Networks (CNNs) with data augmentation has proven successful in increasing the amount of training data at the cost of overfitting. In our research, equivariant neural networks have been used to extend the equivariant properties of CNNs to more transformations than translations. The networks have been trained and evaluated on biomedical image datasets, including bright-field microscopy images of cytological samples indicating oral cancer, and transmission electron microscopy images of virus samples. By designing the networks to be equivariant to e.g. rotations, it is shown that the need for data augmentation is reduced, that less overfitting occurs, and that convergence during training is faster. Furthermore, equivariant neural networks are more data efficient than CNNs, as demonstrated by scaling laws. These benefits are not present in all problem settings and which benefits will occur is somewhat unpredictable. We have identified that the results to some extent depend on architectures, hyperparameters and datasets. Further research may broaden the performed studies to explain how the results occur with new theory.
This talk will explain that Convolutional Neural Networks without activation parametrize polynomials that admit a certain sparse factorization. For a fixed network architecture, these polynomials form a semialgebraic set. We will investigate how the geometry of this semialgebraic set (e.g., its singularities and relative boundary) changes with the network architecture. Moreover, we will explore how these geometric properties affect the optimization of a loss function for given training data. We prove that for architectures where all strides are larger than one and generic data, the non-zero critical points of the squared-error loss are smooth interior points of the semialgebraic function space. This property is known to be false for dense linear networks or linear convolutional networks with stride one. (For linear networks, that are equivariant under the action of some group, we prove that no fixed network architecture can parametrize the whole space of functions, but that finitely many architectures can exhaust the whole space of linear equivariant functions.) This talk is based on joint work with Joan Bruna, Guido Montúfar, Anna-Laura Sattelberger, Vahid Shahverdi, and Matthew Trager.