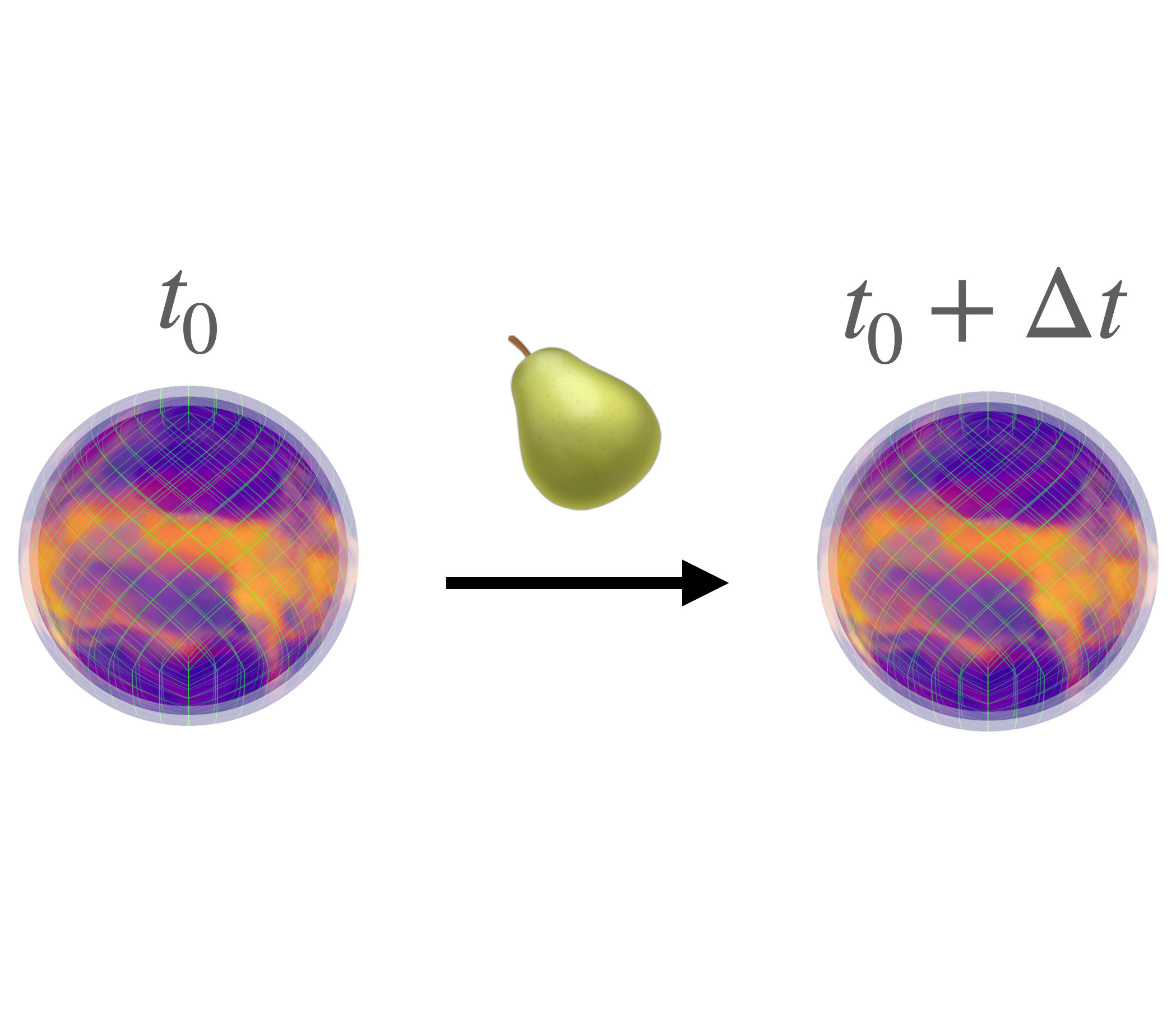Symmetries are important for many deep learning tasks, ranging from applications in the sciences to medical imaging. However, there is an ongoing debate about whether to impose symmetry constraints on the neural network architecture (yielding equivariant neural networks) or learn them from augmented training data. Although equivariant networks are well-studied theoretically, much less is known about data augmentation, since analyzing augmentation requires control over the training dynamics. Inspired by recent results that show that augmented infinite deep ensembles are exactly equivariant, we study data augmentation for Bayesian neural networks (BNNs) trained with variational inference. We focus on variational distributions in the exponential family and derive conditions under which exact equivariance is reached. We furthermore obtain bounds on the equivariance error and introduce three novel symmetrization techniques which boost the effect of data augmentation in this setting. We conduct extensive numerical experiments which show that one of our symmetrization methods (orbit expansion) outperforms the baseline in both equivariance and overall performance. Our code is available at https://github.com/dmw1998/augment-BNNs.
Point cloud learning often rests on the premise that observed samples are noisy traces of an underlying geometric object, such as a manifold embedded in a high-dimensional feature space. Yet much of this geometry is not captured directly by coordinates, pairwise distances, or learned graph neighborhoods alone. In the smooth setting, differential forms are devices to encode higher order tangency information. In this work, we introduce a new family of principled learnable geometric features for point clouds called neural point-forms (NPFs). In the absence of a natural tangency structure, we instead use Laplacian-based techniques from Diffusion Geometry to build a discrete model for comparing differential forms on point clouds via inner products. In the continuum, submanifolds of a shared ambient feature space are represented as comparison matrices, whose entries describe how pairs of feature forms interact with extrinsic tangency information. We make this intuition precise by proving the long-run consistency of comparison matrices under standard sampling, bandwidth, density, and manifold-hypothesis assumptions. This yields a compact, efficient and permutation-invariant neural layer whose output is a learned form-comparison matrix. Across synthetic and biologically relevant experiments, we show that NPFs provide a competitive, and interpretable representation, with the strongest benefits appearing when labels depend on sampling density, manifold-like structure, or response-relevant population geometry.
Diffusion geometry is a manifold learning framework that uses random walks defined by Markov transition matrices to characterize the geometry of a dataset at multiple scales. We use diffusion geometry for neural representations, incorporating tools from multi-view learning into this field for the first time. Our key technical observation is that a broad class of similarity measures based on representational similarity matrices (RSMs) admits a closed-form equivalent formulation in terms of row-stochastic Markov matrices, opening the door to manipulations from diffusion geometry. As a first application, we develop multi-scale variants of Centered Kernel Alignment and Distance Correlation, which utilise the t-th power of the underlying transition matrix to probe the data geometry at adjustable diffusion scales. Going further, we introduce variants of these measures which fuse the Markov matrices of several layers via alternating diffusion into a single operator that captures the network’s joint sample geometry, allowing similarity to be computed across multiple layers and shifting the comparison from layer-to-layer to network-to-network. We perform extensive numerical experiments, evaluating our measures on the Representational Similarity (ReSi) benchmark comprising 14 architectures trained on 7 datasets across three different domains. Our methods achieve SoTA results in accuracy and output correlation for both language and vision tasks across different models. We furthermore show SoTA performance on an additional benchmark evaluating on out-of-distribution data.
We introduce steerable neural ordinary differential equations on homogeneous spaces M = G/H. These models constitute a novel geometric extension of manifold neural ordinary differential equations (NODEs) that transport associated feature vectors transforming under the local symmetry group H. We interpret features as sections of associated vector bundles over M, and describe their evolution as parallel transport. This results in a coupled system of ODEs consisting of a flow equation on M and a steering equation acting on features. We show that steerable NODEs are G-equivariant whenever the vector field generating the flow and the connection governing parallel transport are both G-invariant. Furthermore, we demonstrate how steerable NODEs incorporate existing NODE models and continuous normalizing flows on Lie groups. Our framework provides the geometric foundation for learning continuous-time equivariant dynamics of general vector-valued features on homogeneous spaces.
It has been known for a long time that initializing weight matrices to be orthogonal instead of having i.i.d. Gaussian components can improve training performance. This phenomenon can be analyzed using finite-width corrections, where the infinite-width statistics are supplemented by a power series in 1/width. In particular, recent empirical results by Day et al. show that the tensors appearing in this treatment stabilize for large depth, as opposed to the tensors of i.i.d.-initialized networks. In this article, we derive explicit layer-wise recursion relations for the tensors appearing in the finite-width expansion of the network statistics in the case of orthogonal initializations. We also provide an extension of recently-introduced Feynman diagrams for the corresponding recursions in the i.i.d.-case which are valid to all orders in 1/width. Finally, we show explicitly that the recursions we derive reproduce the stability of the finite-width tensors which was observed for activation functions with vanishing fixed point. This work therefore provides a theoretical explanation for the stability of nonlinear networks of finite width initialized with orthogonal weights, closing a long-standing gap in the literature. We validate our theoretical results experimentally by showing that numerical solutions of our recursion relations and their analytical large-depth expansions agree excellently with Monte-Carlo estimates from network ensembles.
We study polynomial group convolutional neural networks (PGCNNs) for an arbitrary finite group G. In particular, we introduce a new mathematical framework for PGCNNs using the language of graded group algebras. This framework yields two natural parametrizations of the architecture, based on Hadamard and Kronecker products, related by a linear map. We compute the dimension of the associated neuromanifold, verifying that it depends only on the number of layers and the size of the group. We also describe the general fiber of the Kronecker parametrization up to the regular group action and rescaling, and conjecture the analogous description for the Hadamard parametrization. Our conjecture is supported by explicit computations for small groups and shallow networks.
Neural tangent kernels (NTKs) are a powerful tool for analyzing deep, non-linear neural networks. In the infinite-width limit, NTKs can easily be computed for most common architectures, yielding full analytic control over the training dynamics. However, at infinite width, important properties of training such as NTK evolution or feature learning are absent. Nevertheless, finite width effects can be included by computing corrections to the Gaussian statistics at infinite width. We introduce Feynman diagrams for computing finite-width corrections to NTK statistics. These dramatically simplify the necessary algebraic manipulations and enable the computation of layer-wise recursive relations for arbitrary statistics involving preactivations, NTKs and certain higher-derivative tensors (dNTK and ddNTK) required to predict the training dynamics at leading order. We demonstrate the feasibility of our framework by extending stability results for deep networks from preactivations to NTKs and proving the absence of finite-width corrections for scale-invariant nonlinearities such as ReLU on the diagonal of the Gram matrix of the NTK. We validate our results with numerical experiments.
Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu’s success. However, all of these models operate on input data and produce predictions on the Driscoll–Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll–Healy without any computational overhead.
Equivariant neural networks have in recent years become an important technique for guiding architecture selection for neural networks with many applications in domains ranging from medical image analysis to quantum chemistry. In particular, as the most general linear equivariant layers with respect to the regular representation, group convolutions have been highly impactful in numerous applications. Although equivariant architectures have been studied extensively, much less is known about the training dynamics of equivariant neural networks. Concurrently, neural tangent kernels (NTKs) have emerged as a powerful tool to analytically understand the training dynamics of wide neural networks. In this work, we combine these two fields for the first time by giving explicit expressions for NTKs of group convolutional neural networks. In numerical experiments, we demonstrate superior performance for equivariant NTKs over non-equivariant NTKs on a classification task for medical images.
This paper presents a novel framework for non-linear equivariant neural network layers on homogeneous spaces. The seminal work of Cohen et al. on equivariant G-CNNs on homogeneous spaces characterized the representation theory of such layers in the linear setting, finding that they are given by convolutions with kernels satisfying so-called steerability constraints. Motivated by the empirical success of non-linear layers, such as self-attention or input dependent kernels, we set out to generalize these insights to the non-linear setting. We derive generalized steerability constraints that any such layer needs to satisfy and prove the universality of our construction. The insights gained into the symmetry-constrained functional dependence of equivariant operators on feature maps and group elements informs the design of future equivariant neural network layers. We demonstrate how several common equivariant network architectures - G-CNNs, implicit steerable kernel networks, conventional and relative position embedded attention based transformers, and LieTransformers - may be derived from our framework.
Equivariant network architectures are a well-established tool for predicting invariant or equivariant quantities. However, almost all learning problems considered in this context feature a global symmetry, i.e. each point of the underlying space is transformed with the same group element, as opposed to a local gauge symmetry, where each point is transformed with a different group element, exponentially enlarging the size of the symmetry group. Gauge equivariant networks have so far mainly been applied to problems in quantum chromodynamics. Here, we introduce a novel application domain for gauge-equivariant networks in the theory of topological condensed matter physics. We use gauge equivariant networks to predict topological invariants (Chern numbers) of multiband topological insulators. The gauge symmetry of the network guarantees that the predicted quantity is a topological invariant. We introduce a novel gauge equivariant normalization layer to stabilize the training and prove a universal approximation theorem for our setup. We train on samples with trivial Chern number only but show that our models generalize to samples with non-trivial Chern number. We provide various ablations of our setup. Our code is available at this https URL.
In this paper, we develop a manifestly geometric framework for equivariant manifold neural ordinary differential equations (NODEs) and use it to analyse their modelling capabilities for symmetric data. First, we consider the action of a Lie group G on a smooth manifold M and establish the equivalence between equivariance of vector fields, symmetries of the corresponding Cauchy problems, and equivariance of the associated NODEs. We also propose a novel formulation, based on Lie theory for symmetries of differential equations, of the equivariant manifold NODEs in terms of the differential invariants of the action of G on M, which provides an efficient parameterisation of the space of equivariant vector fields in a way that is agnostic to both the manifold M and the symmetry group G. Second, we construct augmented manifold NODEs, through embeddings into flows on the tangent bundle TM, and show that they are universal approximators of diffeomorphisms on any connected M. Furthermore, we show that universality persists in the equivariant case and that the augmented equivariant manifold NODEs can be incorporated into the geometric framework using higher-order differential invariants. Finally, we consider the induced action of G on different fields on M and show how it can be used to generalise previous work, on, e.g., continuous normalizing flows, to equivariant models in any geometry.
We demonstrate that deep ensembles are secretly equivariant models. More precisely, we show that deep ensembles become equivariant for all inputs and at all training times by simply using data augmentation. Crucially, equivariance holds off-manifold and for any architecture in the infinite width limit. The equivariance is emergent in the sense that predictions of individual ensemble members are not equivariant but their collective prediction is. Neural tangent kernel theory is used to derive this result and we verify our theoretical insights using detailed numerical experiments.
Fine-tuning large language models can improve task specific performance, although a general understanding of what the fine-tuned model has learned, forgotten and how to trust its predictions is still missing. We derive principled uncertainty quantification for fine-tuned LLMs with posterior approximations using computationally efficient low-rank adaptation ensembles. We analyze three common multiple-choice datasets using low-rank adaptation ensembles based on Mistral-7b, and draw quantitative and qualitative conclusions on their perceived complexity and model efficacy on the different target domains during and after fine-tuning. In particular, backed by the numerical experiments, we hypothesise about signals from entropic uncertainty measures for data domains that are inherently difficult for a given architecture to learn.
We compute how small input perturbations affect the output of deep neural networks, exploring an analogy between deep feed-forward networks and dynamical systems, where the growth or decay of local perturbations is characterized by finite-time Lyapunov exponents. We show that the maximal exponent forms geometrical structures in input space, akin to coherent structures in dynamical systems. Ridges of large positive exponents divide input space into different regions that the network associates with different classes. These ridges visualize the geometry that deep networks construct in input space, shedding light on the fundamental mechanisms underlying their learning capabilities.
We survey the mathematical foundations of geometric deep learning, focusing on group equivariant and gauge equivariant neural networks. We develop gauge equivariant convolutional neural networks on arbitrary manifolds \(\mathcal{M}\) using principal bundles with structure group K and equivariant maps between sections of associated vector bundles. We also discuss group equivariant neural networks for homogeneous spaces \(\mathcal {M}=G/K\), which are instead equivariant with respect to the global symmetry \(G\) on \(\mathcal {M}\). Group equivariant layers can be interpreted as intertwiners between induced representations of \(G\), and we show their relation to gauge equivariant convolutional layers. We analyze several applications of this formalism, including semantic segmentation and object detection networks. We also discuss the case of spherical networks in great detail, corresponding to the case \(\mathcal {M}=S^2=\textrm{SO}(3)/\textrm{SO}(2)\). Here we emphasize the use of Fourier analysis involving Wigner matrices, spherical harmonics and Clebsch-Gordan coefficients for \(G=\textrm{SO}(3)\), illustrating the power of representation theory for deep learning.
Bayesian inference can quantify uncertainty in the predictions of neural networks using posterior distributions for model parameters and network output. By looking at these posterior distributions, one can separate the origin of uncertainty into aleatoric and epistemic contributions. One goal of uncertainty quantification is to inform on prediction accuracy. Here we show that prediction accuracy depends on both epistemic and aleatoric uncertainty in an intricate fashion that cannot be understood in terms of marginalized uncertainty distributions alone. How the accuracy relates to epistemic and aleatoric uncertainties depends not only on the model architecture, but also on the properties of the dataset. We discuss the significance of these results for active learning and introduce a novel acquisition function that outperforms common uncertainty-based methods. To arrive at our results, we approximated the posteriors using deep ensembles, for fully-connected, convolutional and attention-based neural networks.
High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.
Lattice gauge equivariant convolutional neural networks (L-CNNs) are a framework for convolutional neural networks that can be applied to non-Abelian lattice gauge theories without violating gauge symmetry. We demonstrate how L-CNNs can be equipped with global group equivariance. This allows us to extend the formulation to be equivariant not just under translations but under global lattice symmetries such as rotations and reflections. Additionally, we provide a geometric formulation of L-CNNs and show how convolutions in L-CNNs arise as a special case of gauge equivariant neural networks on SU(N) principal bundles.
We introduce ensembles of stochastic neural networks to approximate the Bayesian posterior, combining stochastic methods such as dropout with deep ensembles. The stochas-tic ensembles are formulated as families of distributions and trained to approximate the Bayesian posterior with variational inference. We implement stochastic ensembles based on Monte Carlo dropout, DropConnect and a novel non-parametric version of dropout and evaluate them on a toy problem and CIFAR image classification. For both tasks, we test the quality of the posteriors directly against Hamil-tonian Monte Carlo simulations. Our results show that stochastic ensembles provide more accurate posterior esti-mates than other popular baselines for Bayesian inference.
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST- or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems.
Counterfactuals can explain classification decisions of neural networks in a human interpretable way. We propose a simple but effective method to generate such counterfactuals. More specifically, we perform a suitable diffeomorphic coordinate transformation and then perform gradient ascent in these coordinates to find counterfactuals which are classified with great confidence as a specified target class. We propose two methods to leverage generative models to construct such suitable coordinate systems that are either exactly or approximately diffeomorphic. We analyze the generation process theoretically using Riemannian differential geometry and validate the quality of the generated counterfactuals using various qualitative and quantitative measures.
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
\(G\)-equivariant convolutional neural networks (GCNNs) is a geometric deep learning model for data defined on a homogeneous \(G\)-space \(\mathcal{M}\). GCNNs are designed to respect the global symmetry in \(\mathcal{M}\), thereby facilitating learning. In this paper, we analyze GCNNs on homogeneous spaces \(\mathcal{M} = G/K\) in the case of unimodular Lie groups \(G\) and compact subgroups \(K \leq G\). We demonstrate that homogeneous vector bundles is the natural setting for GCNNs. We also use reproducing kernel Hilbert spaces to obtain a precise criterion for expressing \(G\)-equivariant layers as convolutional layers. This criterion is then rephrased as a bandwidth criterion, leading to even stronger results for some groups.
We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with convolutional layers on field-programmable gate arrays (FPGAs). By extending the hls4ml library, we demonstrate an inference latency of 5 µs using convolutional architectures, targeting microsecond latency applications like those at the CERN Large Hadron Collider. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device used in trigger and data acquisition systems of particle detectors. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be significantly reduced with little to no loss in model accuracy. We show that the FPGA critical resource consumption can be reduced by 97% with zero loss in model accuracy, and by 99% when tolerating a 6% accuracy degradation.