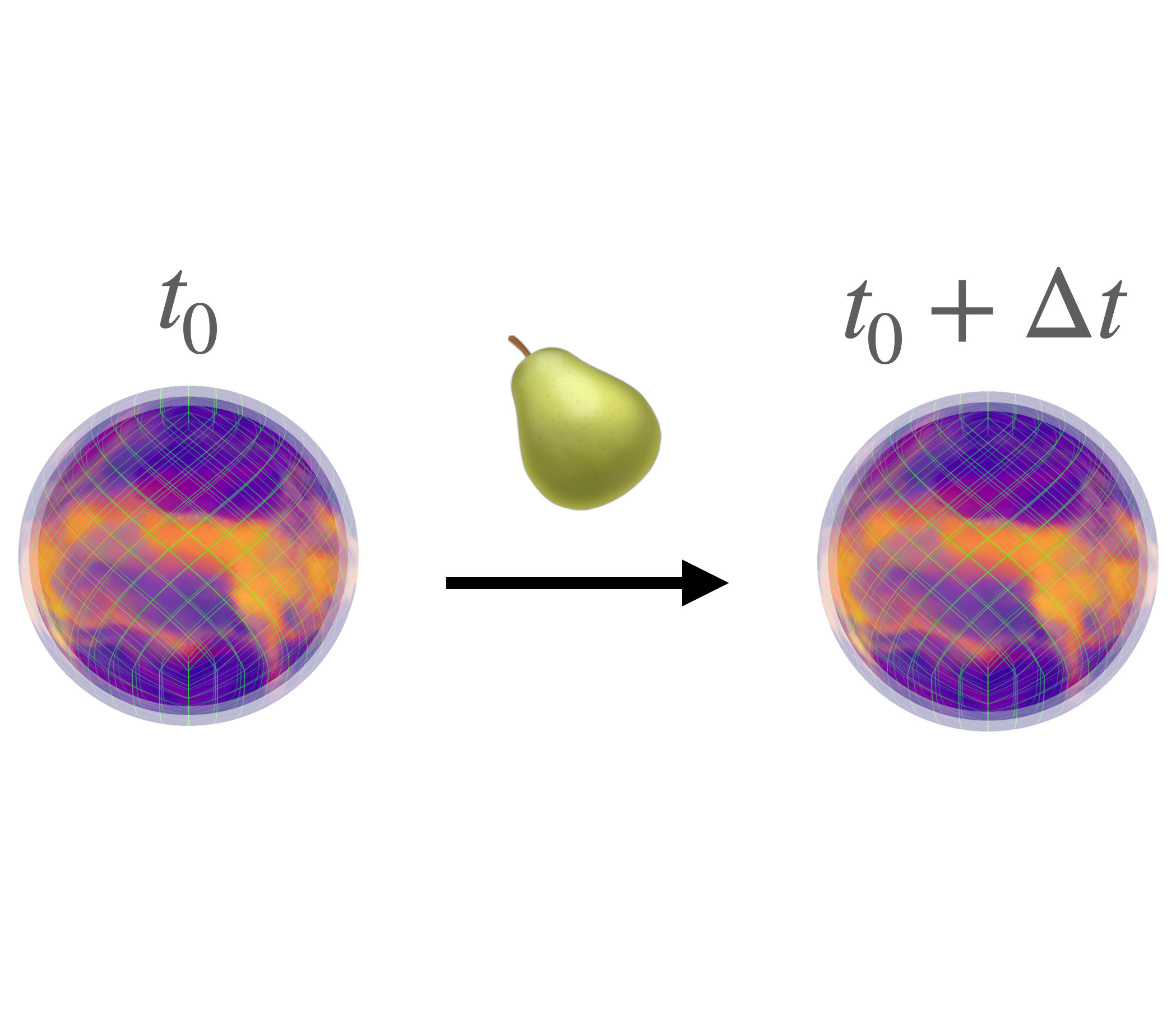Hampus Linander
Researcher at Verses AI


About me
I am a machine learning researcher specializing in geometric deep learning and uncertainty quantification for artificial neural networks.
My journey began with a PhD in theoretical physics, where I explored string theory and higher spin using symbolic computational methods. I have developed perception models for autonomous driving using artificial neural networks and researched interdisciplinary problems in machine learning, mathematics, physics and computer science.
Publications
PEAR: Equal Area Weather Forecasting on the Sphere #
Hampus Linander, Christoffer Petersson, Daniel Persson, Jan E. Gerken
Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu’s success. However, all of these models operate on input data and produce predictions on the Driscoll–Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll–Healy without any computational overhead.
Learning Chern Numbers of Topological Insulators with Gauge Equivariant Neural Networks #
Longde Huang, Oleksandr Balabanov, Hampus Linander, Mats Granath, Daniel Persson, Jan E. Gerken
Equivariant network architectures are a well-established tool for predicting invariant or equivariant quantities. However, almost all learning problems considered in this context feature a global symmetry, i.e. each point of the underlying space is transformed with the same group element, as opposed to a local gauge symmetry, where each point is transformed with a different group element, exponentially enlarging the size of the symmetry group. Gauge equivariant networks have so far mainly been applied to problems in quantum chromodynamics. Here, we introduce a novel application domain for gauge-equivariant networks in the theory of topological condensed matter physics. We use gauge equivariant networks to predict topological invariants (Chern numbers) of multiband topological insulators. The gauge symmetry of the network guarantees that the predicted quantity is a topological invariant. We introduce a novel gauge equivariant normalization layer to stabilize the training and prove a universal approximation theorem for our setup. We train on samples with trivial Chern number only but show that our models generalize to samples with non-trivial Chern number. We provide various ablations of our setup. Our code is available at this https URL.
Uncertainty quantification in fine-tuned LLMs using LoRA ensembles #
Oleksandr Balabanov, Hampus Linander
Fine-tuning large language models can improve task specific performance, although a general understanding of what the fine-tuned model has learned, forgotten and how to trust its predictions is still missing. We derive principled uncertainty quantification for fine-tuned LLMs with posterior approximations using computationally efficient low-rank adaptation ensembles. We analyze three common multiple-choice datasets using low-rank adaptation ensembles based on Mistral-7b, and draw quantitative and qualitative conclusions on their perceived complexity and model efficacy on the different target domains during and after fine-tuning. In particular, backed by the numerical experiments, we hypothesise about signals from entropic uncertainty measures for data domains that are inherently difficult for a given architecture to learn.
Finite-Time Lyapunov Exponents of Deep Neural Networks #
Ludvig Storm, Hampus Linander, Jeremy Bec, Kristian Gustavsson, Bernhard Mehlig
We compute how small input perturbations affect the output of deep neural networks, exploring an analogy between deep feed-forward networks and dynamical systems, where the growth or decay of local perturbations is characterized by finite-time Lyapunov exponents. We show that the maximal exponent forms geometrical structures in input space, akin to coherent structures in dynamical systems. Ridges of large positive exponents divide input space into different regions that the network associates with different classes. These ridges visualize the geometry that deep networks construct in input space, shedding light on the fundamental mechanisms underlying their learning capabilities.
Geometric deep learning and equivariant neural networks #
Jan E. Gerken, Jimmy Aronsson, Oscar Carlsson, Hampus Linander, Fredrik Ohlsson, Christoffer Petersson, Daniel Persson
We survey the mathematical foundations of geometric deep learning, focusing on group equivariant and gauge equivariant neural networks. We develop gauge equivariant convolutional neural networks on arbitrary manifolds \(\mathcal{M}\) using principal bundles with structure group K and equivariant maps between sections of associated vector bundles. We also discuss group equivariant neural networks for homogeneous spaces \(\mathcal {M}=G/K\), which are instead equivariant with respect to the global symmetry \(G\) on \(\mathcal {M}\). Group equivariant layers can be interpreted as intertwiners between induced representations of \(G\), and we show their relation to gauge equivariant convolutional layers. We analyze several applications of this formalism, including semantic segmentation and object detection networks. We also discuss the case of spherical networks in great detail, corresponding to the case \(\mathcal {M}=S^2=\textrm{SO}(3)/\textrm{SO}(2)\). Here we emphasize the use of Fourier analysis involving Wigner matrices, spherical harmonics and Clebsch-Gordan coefficients for \(G=\textrm{SO}(3)\), illustrating the power of representation theory for deep learning.
Looking at the posterior: accuracy and uncertainty of neural-network predictions #
Hampus Linander, Oleksandr Balabanov, Henry Yang, Bernhard Mehlig
Bayesian inference can quantify uncertainty in the predictions of neural networks using posterior distributions for model parameters and network output. By looking at these posterior distributions, one can separate the origin of uncertainty into aleatoric and epistemic contributions. One goal of uncertainty quantification is to inform on prediction accuracy. Here we show that prediction accuracy depends on both epistemic and aleatoric uncertainty in an intricate fashion that cannot be understood in terms of marginalized uncertainty distributions alone. How the accuracy relates to epistemic and aleatoric uncertainties depends not only on the model architecture, but also on the properties of the dataset. We discuss the significance of these results for active learning and introduce a novel acquisition function that outperforms common uncertainty-based methods. To arrive at our results, we approximated the posteriors using deep ensembles, for fully-connected, convolutional and attention-based neural networks.
HEAL-SWIN: A Vision Transformer On The Sphere #
Oscar Carlsson, Jan E. Gerken, Hampus Linander, Heiner Spieß, Fredrik Ohlsson, Christoffer Petersson, Daniel Persson
High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.
Bayesian posterior approximation with stochastic ensembles #
Oleksandr Balabanov, Bernhard Mehlig, Hampus Linander
We introduce ensembles of stochastic neural networks to approximate the Bayesian posterior, combining stochastic methods such as dropout with deep ensembles. The stochas-tic ensembles are formulated as families of distributions and trained to approximate the Bayesian posterior with variational inference. We implement stochastic ensembles based on Monte Carlo dropout, DropConnect and a novel non-parametric version of dropout and evaluate them on a toy problem and CIFAR image classification. For both tasks, we test the quality of the posteriors directly against Hamil-tonian Monte Carlo simulations. Our results show that stochastic ensembles provide more accurate posterior esti-mates than other popular baselines for Bayesian inference.
Equivariance versus Augmentation for Spherical Images #
Jan E. Gerken, Oscar Carlsson, Hampus Linander, Fredrik Ohlsson, Christoffer Petersson, Daniel Persson
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST- or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml #
Nicolò Ghielmetti, Vladimir Loncar, Maurizio Pierini, Marcel Roed, Sioni Summers, Thea Aarrestad, Christoffer Petersson, Hampus Linander, Jennifer Ngadiuba, Kelvin Lin
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
Fast convolutional neural networks on FPGAs with hls4ml #
Thea Aarrestad, Vladimir Loncar, Nicolò Ghielmetti, Maurizio Pierini, Sioni Summers, Jennifer Ngadiuba, Christoffer Petersson, Hampus Linander, Yutaro Iiyama, Giuseppe Di Guglielmo
We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with convolutional layers on field-programmable gate arrays (FPGAs). By extending the hls4ml library, we demonstrate an inference latency of 5 µs using convolutional architectures, targeting microsecond latency applications like those at the CERN Large Hadron Collider. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device used in trigger and data acquisition systems of particle detectors. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be significantly reduced with little to no loss in model accuracy. We show that the FPGA critical resource consumption can be reduced by 97% with zero loss in model accuracy, and by 99% when tolerating a 6% accuracy degradation.
The non-linear coupled spin 2-spin 3 Cotton equation in three dimensions #
Hampus Linander, Bengt EW Nilsson
In the context of three-dimensional conformal higher spin theory we derive, in the frame field formulation, the full non-linear spin 3 Cotton equation coupled to spin 2. This is done by solving the corresponding Chern-Simons gauge theory system of equations, that is, using F = 0 to eliminate all auxiliary fields and thus expressing the Cotton equation in terms of just the spin 3 frame field and spin 2 covariant derivatives and tensors (Schouten). In this derivation we neglect the spin 4 and higher spin sectors and approximate the star product commutator by a Poisson bracket. The resulting spin 3 Cotton equation is complicated but can be related to linearized versions in the metric formulation obtained previously by other authors. The expected symmetry (spin 3 “translation”, “Lorentz” and “dilatation”) properties are verified for Cotton and other relevant tensors but some perhaps unexpected features emerge in the process, in particular in relation to the non-linear equations. We discuss the structure of this non-linear spin 3 Cotton equation but its explicit form is only presented here, in an exact but not completely refined version, in appended files obtained by computer algebra methods. Both the frame field and metric formulations are provided.
The trouble with twisting (2, 0) theory #
Louise Anderson, Hampus Linander
We consider a twisted version of the abelian (2, 0) theory placed upon a Lorentzian six-manifold with a product structure, \(M_6 = C \times M_4\). This is done by an investigation of the free tensor multiplet on the level of equations of motion, where the problem of its formulation in Euclidean signature is circumvented by letting the time-like direction lie in the two-manifold \(C\) and performing a topological twist along \(M_4\) alone. A compactification on \(C\) is shown to be necessary to enable the possibility of finding a topological field theory. The hypothetical twist along a Euclidean \(C\) is argued to amount to the correct choice of linear combination of the two supercharges scalar on \(M_4\). This procedure is expected and conjectured to result in a topological field theory, but we arrive at the surprising conclusion that this twisted theory contains no \(Q\)-exact and covariantly conserved stress tensor unless \(M_4\) has vanishing curvature. This is to our knowledge a phenomenon which has not been observed before in topological field theories. In the literature, the setup of the twisting used here has been suggested as the origin of the conjectured AGT-correspondence, and our hope is that this work may somehow contribute to the understanding of it.
Off-shell structure of twisted (2, 0) theory #
Ulf Gran, Hampus Linander, Bengt EW Nilsson
A \(Q\)-exact off-shell action is constructed for twisted abelian (2,0) theory on a Lorentzian six-manifold of the form \(M_{1,5} = C \times M_4\), where \(C\) is a flat two-manifold and \(M_4\) is a general Euclidean four-manifold. The properties of this formulation, which is obtained by introducing two auxiliary fields, can be summarised by a commutative diagram where the Lagrangian and its stress-tensor arise from the \(Q\)-variation of two fermionic quantities \(V\) and \(\lambda^{\mu\nu}\). This completes and extends the analysis in [1].
(2, 0) theory on circle fibrations #
Hampus Linander, Fredrik Ohlsson
We consider (2, 0) theory on a manifold \(M_6\) that is a fibration of a spatial \(S^1\) over some five-dimensional base manifold \(M_5\). Initially, we study the free (2, 0) tensor multiplet which can be described in terms of classical equations of motion in six dimensions. Given a metric on \(M_6\) the low energy effective theory obtained through dimensional reduction on the circle is a Maxwell theory on \(M_5\). The parameters describing the local geometry of the fibration are interpreted respectively as the metric on \(M_5\), a non-dynamical \(U(1)\) gauge field and the coupling strength of the resulting low energy Maxwell theory. We derive the general form of the action of the Maxwell theory by integrating the reduced equations of motion, and consider the symmetries of this theory originating from the superconformal symmetry in six dimensions. Subsequently, we consider a non-abelian generalization of the Maxwell theory on \(M_5\). Completing the theory with Yukawa and \(\phi^4\) terms, and suitably modifying the supersymmetry transformations, we obtain a supersymmetric Yang-Mills theory which includes terms related to the geometry of the fibration.