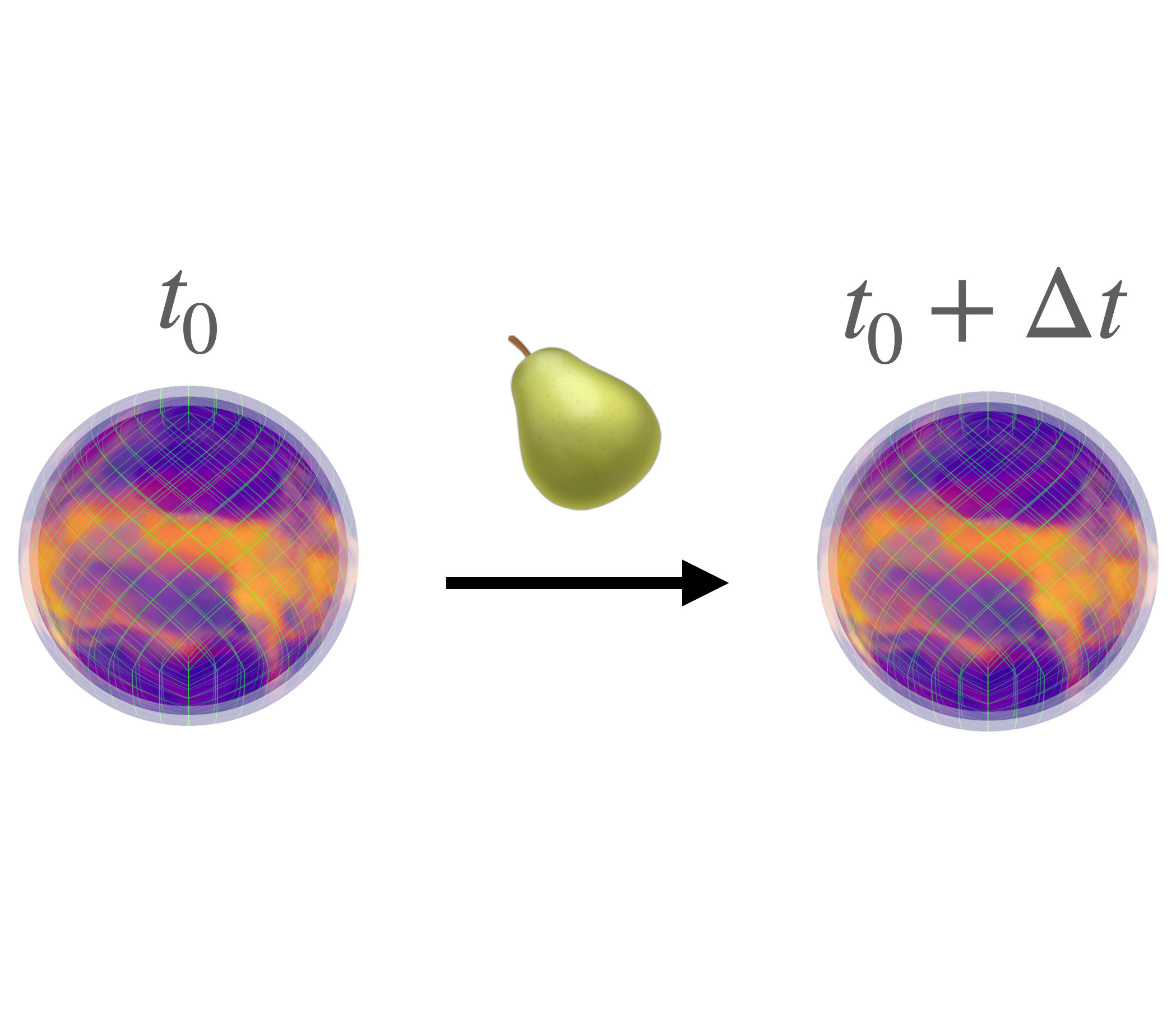Christoffer Petersson
Founder and CEO of Recohere, Adjunct Associate Professor at Chalmers


About me
I am the Founder and CEO of Recohere, a company that automates the creation of high-fidelity digital twins using neural rendering techniques such as Neural Radiance Fields (NeRFs) and 3D Gaussian Splatting, with applications in autonomous driving simulation. I also hold the position of Adjunct Associate Professor in Machine Learning at Chalmers University of Technology.
My background in string theory and theoretical particle physics, acquired through my PhD at Chalmers and research positions at CERN, Madrid, and Brussels, has evolved into a focus on deep learning for autonomous driving, specifically in perception, prediction, planning, and simulation, with the overarching goal to eliminate road traffic crashes.
In my adjunct role, I’m particularly interested in the theoretical underpinnings of deep learning, with a focus on geometric deep learning and equivariant neural networks. My research aims to leverage symmetries to improve learning efficiency for complex, high-dimensional data, particularly in data-limited scenarios. I am driven to bridge theoretical advancements with real-world applications to enhance the robustness and scalability of deep learning across both academic and industrial domains.
Below are my publications in collaboration with the GAPinDNNs research group at Chalmers.
For a complete list of my publications, please visit my profiles on Google Scholar and arXiv.
Publications
PEAR: Equal Area Weather Forecasting on the Sphere #
Hampus Linander, Christoffer Petersson, Daniel Persson, Jan E. Gerken
Machine learning methods for global medium-range weather forecasting have recently received immense attention. Following the publication of the Pangu Weather model, the first deep learning model to outperform traditional numerical simulations of the atmosphere, numerous models have been published in this domain, building on Pangu’s success. However, all of these models operate on input data and produce predictions on the Driscoll–Healy discretization of the sphere which suffers from a much finer grid at the poles than around the equator. In contrast, in the Hierarchical Equal Area iso-Latitude Pixelization (HEALPix) of the sphere, each pixel covers the same surface area, removing unphysical biases. Motivated by a growing support for this grid in meteorology and climate sciences, we propose to perform weather forecasting with deep learning models which natively operate on the HEALPix grid. To this end, we introduce Pangu Equal ARea (PEAR), a transformer-based weather forecasting model which operates directly on HEALPix-features and outperforms the corresponding model on Driscoll–Healy without any computational overhead.
Geometric deep learning and equivariant neural networks #
Jan E. Gerken, Jimmy Aronsson, Oscar Carlsson, Hampus Linander, Fredrik Ohlsson, Christoffer Petersson, Daniel Persson
We survey the mathematical foundations of geometric deep learning, focusing on group equivariant and gauge equivariant neural networks. We develop gauge equivariant convolutional neural networks on arbitrary manifolds \(\mathcal{M}\) using principal bundles with structure group K and equivariant maps between sections of associated vector bundles. We also discuss group equivariant neural networks for homogeneous spaces \(\mathcal {M}=G/K\), which are instead equivariant with respect to the global symmetry \(G\) on \(\mathcal {M}\). Group equivariant layers can be interpreted as intertwiners between induced representations of \(G\), and we show their relation to gauge equivariant convolutional layers. We analyze several applications of this formalism, including semantic segmentation and object detection networks. We also discuss the case of spherical networks in great detail, corresponding to the case \(\mathcal {M}=S^2=\textrm{SO}(3)/\textrm{SO}(2)\). Here we emphasize the use of Fourier analysis involving Wigner matrices, spherical harmonics and Clebsch-Gordan coefficients for \(G=\textrm{SO}(3)\), illustrating the power of representation theory for deep learning.
HEAL-SWIN: A Vision Transformer On The Sphere #
Oscar Carlsson, Jan E. Gerken, Hampus Linander, Heiner Spieß, Fredrik Ohlsson, Christoffer Petersson, Daniel Persson
High-resolution wide-angle fisheye images are becoming more and more important for robotics applications such as autonomous driving. However, using ordinary convolutional neural networks or vision transformers on this data is problematic due to projection and distortion losses introduced when projecting to a rectangular grid on the plane. We introduce the HEAL-SWIN transformer, which combines the highly uniform Hierarchical Equal Area iso-Latitude Pixelation (HEALPix) grid used in astrophysics and cosmology with the Hierarchical Shifted-Window (SWIN) transformer to yield an efficient and flexible model capable of training on high-resolution, distortion-free spherical data. In HEAL-SWIN, the nested structure of the HEALPix grid is used to perform the patching and windowing operations of the SWIN transformer, resulting in a one-dimensional representation of the spherical data with minimal computational overhead. We demonstrate the superior performance of our model for semantic segmentation and depth regression tasks on both synthetic and real automotive datasets. Our code is available at https://github.com/JanEGerken/HEAL-SWIN.
Equivariance versus Augmentation for Spherical Images #
Jan E. Gerken, Oscar Carlsson, Hampus Linander, Fredrik Ohlsson, Christoffer Petersson, Daniel Persson
We analyze the role of rotational equivariance in convolutional neural networks (CNNs) applied to spherical images. We compare the performance of the group equivariant networks known as S2CNNs and standard non-equivariant CNNs trained with an increasing amount of data augmentation. The chosen architectures can be considered baseline references for the respective design paradigms. Our models are trained and evaluated on single or multiple items from the MNIST- or FashionMNIST dataset projected onto the sphere. For the task of image classification, which is inherently rotationally invariant, we find that by considerably increasing the amount of data augmentation and the size of the networks, it is possible for the standard CNNs to reach at least the same performance as the equivariant network. In contrast, for the inherently equivariant task of semantic segmentation, the non-equivariant networks are consistently outperformed by the equivariant networks with significantly fewer parameters. We also analyze and compare the inference latency and training times of the different networks, enabling detailed tradeoff considerations between equivariant architectures and data augmentation for practical problems.
Real-time semantic segmentation on FPGAs for autonomous vehicles with hls4ml #
Nicolò Ghielmetti, Vladimir Loncar, Maurizio Pierini, Marcel Roed, Sioni Summers, Thea Aarrestad, Christoffer Petersson, Hampus Linander, Jennifer Ngadiuba, Kelvin Lin
In this paper, we investigate how field programmable gate arrays can serve as hardware accelerators for real-time semantic segmentation tasks relevant for autonomous driving. Considering compressed versions of the ENet convolutional neural network architecture, we demonstrate a fully-on-chip deployment with a latency of 4.9 ms per image, using less than 30% of the available resources on a Xilinx ZCU102 evaluation board. The latency is reduced to 3 ms per image when increasing the batch size to ten, corresponding to the use case where the autonomous vehicle receives inputs from multiple cameras simultaneously. We show, through aggressive filter reduction and heterogeneous quantization-aware training, and an optimized implementation of convolutional layers, that the power consumption and resource utilization can be significantly reduced while maintaining accuracy on the Cityscapes dataset.
Fast convolutional neural networks on FPGAs with hls4ml #
Thea Aarrestad, Vladimir Loncar, Nicolò Ghielmetti, Maurizio Pierini, Sioni Summers, Jennifer Ngadiuba, Christoffer Petersson, Hampus Linander, Yutaro Iiyama, Giuseppe Di Guglielmo
We introduce an automated tool for deploying ultra low-latency, low-power deep neural networks with convolutional layers on field-programmable gate arrays (FPGAs). By extending the hls4ml library, we demonstrate an inference latency of 5 µs using convolutional architectures, targeting microsecond latency applications like those at the CERN Large Hadron Collider. Considering benchmark models trained on the Street View House Numbers Dataset, we demonstrate various methods for model compression in order to fit the computational constraints of a typical FPGA device used in trigger and data acquisition systems of particle detectors. In particular, we discuss pruning and quantization-aware training, and demonstrate how resource utilization can be significantly reduced with little to no loss in model accuracy. We show that the FPGA critical resource consumption can be reduced by 97% with zero loss in model accuracy, and by 99% when tolerating a 6% accuracy degradation.